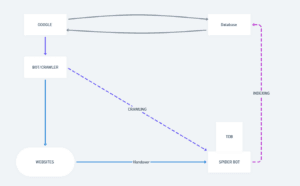
Above image is the diagrammatic illustration of how google search engine works – a basic bird eye view
Each component have a purpose and work listed, so we gonna understand them each, one by one.
This is the brain — the main system that controls everything. It decides which websites to visit, stores information, and serves search results to users. It is more easy to refer is as google interface which you see on google.com
BOT / CRAWLER / ROBOT
- Crawlers are the programs/bots which visit the websites and collect the data and process them further.
As in general crawlers can be individually made by any company or the resourceful full person for prospective tasks. - In simple words, we can mark that google will send the bot to the website, the BOT then will collect the data of the website and then will handover that data to the spider.
WEBSITES
These are all the pages on the internet — like sports sites, news sites, blogs, etc. The crawler visits these pages to read their content.
SPIDER BOT
- A more specialized crawler. Once the main Bot/Crawler finds a website, it hands the actual deep-reading job over to the Spider Bot. The Spider Bot goes page by page, link by link, reading everything.
- Spider bot is also an another crawler by google, which have different works
- Maintaining the TDB – (TEMPORARY DATABASE ) Here the spider have to manage the temporary database
- It checks which information was already available in the temporary database
- Plus – the information which is not available in the temporary database.
- Now, finally when spider bot analyse and find out that the information that is supplied by main bot, is already in the temporary database, it provides zero value to that information
- And it saves the new information, which is provided by the main bot.
- Then it makes a final report and uploads that information in the Database.
Database
Google’s giant storage. Everything the Spider Bot reads and processes gets saved here. This is where Google keeps its copy of the internet.
WORKFLOW
- Ujjawal search something on the google let say “ What is SEO”
- This triggers the action and this query goes to Database
- Now google will find the relevant information related to the query
- Then, display the answer in the google interface[ on display]

CRAWLING & INDEXING
CRAWLING
(The purple dashed diagonal arrow — from BOT/CRAWLER → to SPIDER BOT)
Google sends its Bot/Crawler → it finds Websites → hands them over → Spider Bot crawls through every page, every link, every word, updates in a temporary database.
In simple words, crawling is just exploring the websites , reading your websites , making a copy in temporary database and submitting the data in further component in the pipeline
INDEXING
(The pink dashed vertical arrow — from SPIDER BOT → up to Database)
This is the saving + organizing phase.
After the Spider Bot finishes reading → it sends all that data up to Google’s Database — this storing process is called Indexing
In simple words indexing is the process where the data is being saved into the database.
At the end, each component in the pipeline has its own work,its uniqueness and its dedicated job.
At the end, each component in the pipeline has its own work,its uniqueness and its dedicated job.